
DNA Sequence Analysis in Bioinformatics:
The term DNA sequencing refers to methods for determining the order of nucleotide bases adenine (A), Thymine (T), Guanine (G) and Cytosine (C) in a molecule of DNA. In some special cases, letters besides A. T, C, and G are present in a sequence. These letters represent ambiguity. Of all the molecules sampled, there is more than one kind of nucleotide at that position. The advent of DNA sequencing has significantly accelerated biological research and helped scientific discovery in a great extent. The analysis of DNA sequence helps in many research areas such as forensic biology, biotechnology etc. With the advent of modern sequencing tools, the speed of sequences increased rapidly it helped major projects such as Human Genome Project. Sequence analysis and its collection can increase the scientists understanding of the biology of various organisms. Nowadays there are many tools and methods to provide sequence comparisons and sequence alignments. Usually it is an automated computer based examination. DNA sequence analysis basically includes the following areas.
A DNA sequence trace is shown below.
The rules of the International Union of Pure and Applied Chemistry (IUPAC) are as follows for representing different nucleotide bases.
• A = adenine
• C = cytosine
• G = guanine
• T = thymine
• R = G A (purine)
• Y = T C (pyrimidine)
• K = G T (keto)
• M = A C (amino)
• S = G C (strong bonds)
• NV =A T (weak bonds)
• B = GTC (all but A)
• D = GAT (all but C)
• H =AC T (all but G)
• V = G CA (all but T)
• N = A G C T (any)
a) The comparison of sequences in order to find similar and dissimilar sequence alignments.
b) The identification of gene structures, introns, exons, reading frames etc
c) Finding and comparing the point mutations or single nucleotide polymorphism (SNP) in organism.
d) Revealing the evolution and genetic diversity of organisms.
Gene Structure and DNA Sequences:
DNA sequence databases typically contain genomic sequence data which includes information about the untranslated sequences.
Features of DNA Sequence Analysis:
The main features of DNA sequence analysis are
Detecting Open Reading Frames (ORF):
ORF (Open Reading Frames) are the longest frame uninterrupted by a stop codon. Finding the end of an ORF is easier than finding its beginning. Actually ORF is used to encode a known gene and it consists of a series of DNA codons which includes an initiation codon and termination codon
Understanding the effect introns and exons:
Introne is a sequence of DNA bases that interrupts the protein coding sequence of a gene and Exones are protein coding sequence of gene.
DNA Sequence assembly:
Another important field of sequence analysis is to determine the nucleotide sequence of a clone. Clone is actually a copied fragment of a DNA. Usually a sequence, which is a acceptable to all is produced with the help of an assembler program. The program generates the code according to weight given to each nucleotide position.
Effects of EST (Expressed Sequence Tag) data on DNA databases
A large part of currently available DNA data is made up of partial sequences. They are called expressed sequence tags (ESTs). ESTs are randomly selected from a DNA library and are used to identify genes expressed in a particular tissue. EST production is highly automated and it results in missing bases. This gives rise to difficulties in sequence finding. ESTs are incomplete and some cases inaccurate. ESTs add a factor of faults to databases because there is always some degree of uncertainly.
EST analysis tools.
There are many tools available for the analysis of ESTs.
a) Sequence similarity search tools.
b) Sequence assembly tools.
c) Sequence combining (clustering) tools.
Sequence similarity search tools: are used to search the similarity between sequences. In order to find the similarity of sequences different methods such as dot-plot representation etc are used.
Sequence assembly tools: When a search of databases reveals several ESTs matching with a sequence, normally the ESTs must be aligned with each other to reveal the sequence. This type of sequence alignment is to be called a sequence assembly. Ex:- TIGR assembler.
Sequence clustering tools: The main purpose of sequence clustering tools is to save the data base search time. Sequence clustering tools take a large set of sequences and divide them into clusters. A reliable and effective mechanism for clustering ESTs will save the database search time and analysis efforts. Such tools are valuable when large numbers of ESTs are generated. In Bioinformatics sequence clustering algorithms attempt to group sequences that are somehow related. For proteins homologous sequences are typically grouped into families.
The term DNA sequencing refers to methods for determining the order of nucleotide bases adenine (A), Thymine (T), Guanine (G) and Cytosine (C) in a molecule of DNA. In some special cases, letters besides A. T, C, and G are present in a sequence. These letters represent ambiguity. Of all the molecules sampled, there is more than one kind of nucleotide at that position. The advent of DNA sequencing has significantly accelerated biological research and helped scientific discovery in a great extent. The analysis of DNA sequence helps in many research areas such as forensic biology, biotechnology etc. With the advent of modern sequencing tools, the speed of sequences increased rapidly it helped major projects such as Human Genome Project. Sequence analysis and its collection can increase the scientists understanding of the biology of various organisms. Nowadays there are many tools and methods to provide sequence comparisons and sequence alignments. Usually it is an automated computer based examination. DNA sequence analysis basically includes the following areas.
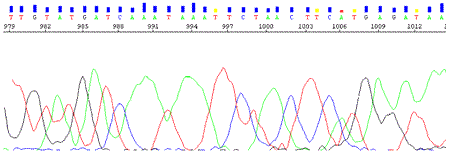 |
| DNA Sequence trace |
The rules of the International Union of Pure and Applied Chemistry (IUPAC) are as follows for representing different nucleotide bases.
• A = adenine
• C = cytosine
• G = guanine
• T = thymine
• R = G A (purine)
• Y = T C (pyrimidine)
• K = G T (keto)
• M = A C (amino)
• S = G C (strong bonds)
• NV =A T (weak bonds)
• B = GTC (all but A)
• D = GAT (all but C)
• H =AC T (all but G)
• V = G CA (all but T)
• N = A G C T (any)
a) The comparison of sequences in order to find similar and dissimilar sequence alignments.
b) The identification of gene structures, introns, exons, reading frames etc
c) Finding and comparing the point mutations or single nucleotide polymorphism (SNP) in organism.
d) Revealing the evolution and genetic diversity of organisms.
Gene Structure and DNA Sequences:
DNA sequence databases typically contain genomic sequence data which includes information about the untranslated sequences.
Features of DNA Sequence Analysis:
The main features of DNA sequence analysis are
Detecting Open Reading Frames (ORF):
ORF (Open Reading Frames) are the longest frame uninterrupted by a stop codon. Finding the end of an ORF is easier than finding its beginning. Actually ORF is used to encode a known gene and it consists of a series of DNA codons which includes an initiation codon and termination codon
Understanding the effect introns and exons:
Introne is a sequence of DNA bases that interrupts the protein coding sequence of a gene and Exones are protein coding sequence of gene.
DNA Sequence assembly:
Another important field of sequence analysis is to determine the nucleotide sequence of a clone. Clone is actually a copied fragment of a DNA. Usually a sequence, which is a acceptable to all is produced with the help of an assembler program. The program generates the code according to weight given to each nucleotide position.
Effects of EST (Expressed Sequence Tag) data on DNA databases
A large part of currently available DNA data is made up of partial sequences. They are called expressed sequence tags (ESTs). ESTs are randomly selected from a DNA library and are used to identify genes expressed in a particular tissue. EST production is highly automated and it results in missing bases. This gives rise to difficulties in sequence finding. ESTs are incomplete and some cases inaccurate. ESTs add a factor of faults to databases because there is always some degree of uncertainly.
EST analysis tools.
There are many tools available for the analysis of ESTs.
a) Sequence similarity search tools.
b) Sequence assembly tools.
c) Sequence combining (clustering) tools.
Sequence similarity search tools: are used to search the similarity between sequences. In order to find the similarity of sequences different methods such as dot-plot representation etc are used.
Sequence assembly tools: When a search of databases reveals several ESTs matching with a sequence, normally the ESTs must be aligned with each other to reveal the sequence. This type of sequence alignment is to be called a sequence assembly. Ex:- TIGR assembler.
Sequence clustering tools: The main purpose of sequence clustering tools is to save the data base search time. Sequence clustering tools take a large set of sequences and divide them into clusters. A reliable and effective mechanism for clustering ESTs will save the database search time and analysis efforts. Such tools are valuable when large numbers of ESTs are generated. In Bioinformatics sequence clustering algorithms attempt to group sequences that are somehow related. For proteins homologous sequences are typically grouped into families.